Semaphore is a robust and efficient CI/CD platform designed to streamline software delivery. Whether you’re a solo developer or have a large team, it helps automate builds, tests, and deployments effortlessly. While it appears straightforward on the surface, its underlying architecture is a sophisticated system composed of over 30 microservices, various communication protocols, and a strong infrastructure to ensure seamless pipeline execution.
In this article, we’ll explore the core architecture of Semaphore, break down the CI/CD process from code push to execution, and examine how developers interact with the system.
To find out more, you can listen to the podcast episode above or watch the video. Enjoy!
Understanding Semaphore’s Architecture
Semaphore balances scalability with ease of use, making it an ideal CI/CD solution for teams of any size. Its architecture is built on a distributed system that ensures high performance, fault tolerance, and automation. Let’s explore the core technologies that power Semaphore’s reliability, scalability, and efficiency.
Core Technologies
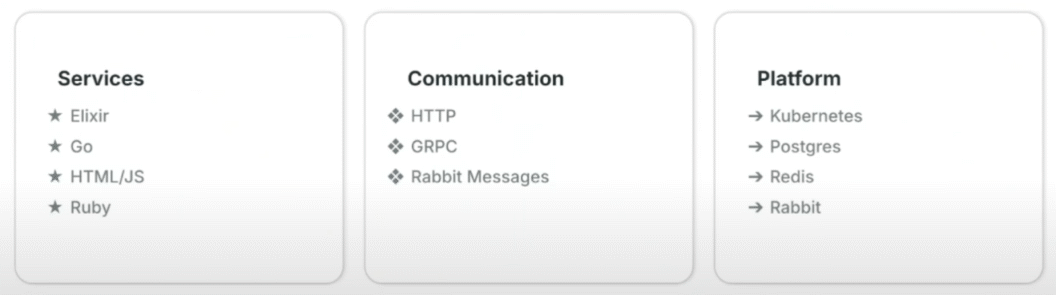
Semaphore is powered by Elixir, which is known for its ability to handle massive concurrency and fault-tolerant systems, making it well-suited for orchestrating thousands of CI/CD jobs. We also leverage Go for performance-critical services and are gradually replacing legacy Ruby components with Elixir. The UI layer uses JavaScript & HTML for seamless developer interaction.
- Elixir: Ideal for building highly concurrent, distributed, and fault-tolerant systems that can efficiently manage thousands of jobs in parallel.
- Go: Used in performance-critical areas where efficiency is paramount.
- Ruby: A legacy component being rewritten in Elixir to align with the rest of the stack.
- JavaScript & HTML: Used for the presentation layer.
How Semaphore Services Talk to Each Other
Semaphore services need to communicate efficiently to process jobs without delay. External interactions happen over HTTP, while gRPC ensures lightning-fast internal messaging. For background tasks, RabbitMQ keeps everything running smoothly behind the scenes.
- gRPC: Provides high-performance internal communication with strict service contracts.
- Proto Files: Define service contracts before implementation to ensure smooth integration.
- RabbitMQ: Enables asynchronous messaging, allowing background tasks to run efficiently.
Scalable and Resilient Infrastructure
Semaphore is built to dynamically handle any workload. Kubernetes orchestrates and scales resources as needed, PostgreSQL stores pipeline and job data efficiently, Redis improves performance with caching, and RabbitMQ ensures smooth communication between services.
These components work together to ensure that Semaphore handles workflows smoothly, balancing speed and reliability. Now, let’s dive into how Semaphore processes CI/CD jobs.
The CI/CD Workflow in Semaphore
Before we dive into the mechanics, let’s break down Semaphore’s two main workflows:
- CI/CD Processing – The backbone of Semaphore, ensuring every code change is built, tested, and deployed.
- CI/CD Management – Where users interact with Semaphore to configure environments, manage projects, and control access.
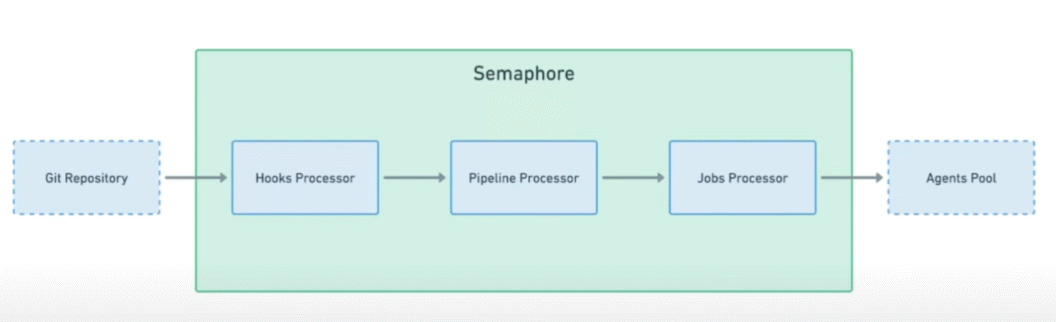
How Semaphore Runs Your CI/CD Workflows
When you push a new commit, Semaphore immediately takes action to ensure a smooth build, test, and deployment process:
- Hook Processing: Semaphore detects the commit, verifies authenticity, and prepares it for execution.
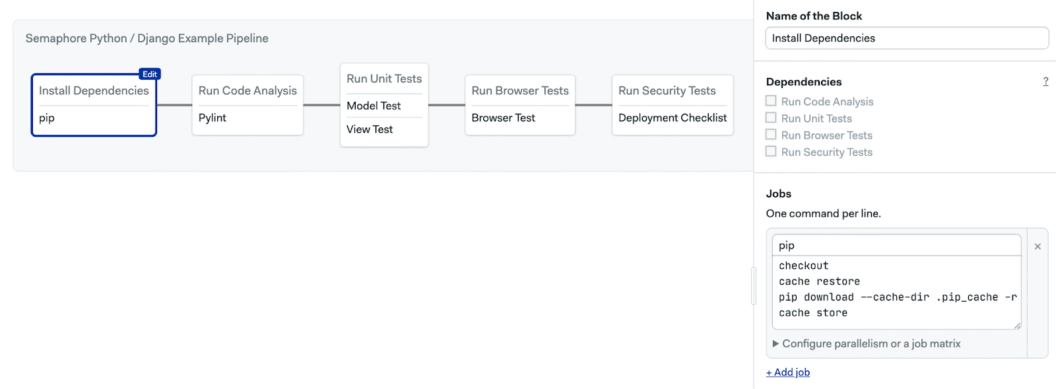
- Pipeline Processing: The Plumber Service reads the YAML configuration, organizes dependencies, and orchestrates job execution.
- Job Execution: The Zebra Service assigns jobs to available agents, tracks execution, and ensures tasks complete on time.
- Notifying External Systems: Semaphore updates integrations like Slack or GitHub to keep you informed.
Workflow Steps
1. Hook Processing
First, Hook Processing begins by listening for incoming events. The Hook Receiver accepts webhooks from Git repositories and verifies authenticity, while the Hook Processor enriches the data, converts it into an internal format, and stores it for traceability.
2. Pipeline Processing
Once a webhook is validated, Semaphore interprets the pipeline definition and orchestrates execution.
- Plumber Service: Defines the pipeline structure based on the YAML configuration, ensuring proper sequencing of jobs.
- Dependency Management: Ensures jobs run in the correct order and do not execute prematurely.
3. Job Execution
Next, the job executes. The following components make this happen:
- Zebra Service: Assigns jobs to available agents, gathers necessary resources, and tracks job states.
- Agents: Execute jobs with the necessary environment and configurations.
- Timeout Management: If a job exceeds the execution time, Zebra forcefully terminates it to prevent queue blocking.
4. Notifying External Systems
Once execution completes, Semaphore updates external systems:
- Notification Service: Sends real-time updates via Slack or webhooks.
- GitHub Notifier: Updates commit statuses in the version control system.
Additional Job Execution Methods
Beyond code pushes, developers can:
- Rerun Pipelines: Re-execute workflows without new commits.
- Start Debug Jobs: Run specific jobs in isolation for debugging.
Managing Your CI/CD Environment in Semaphore
Beyond executing jobs, Semaphore gives developers full control over their CI/CD workflows, including environment configurations, user permissions, and system integrations. Let’s dive into how you can optimize your setup.
User Interaction with Semaphore
Users interact with Semaphore through the UI and API, with HTTP handling external communication and gRPC managing internal services.
Keeping Semaphore Secure
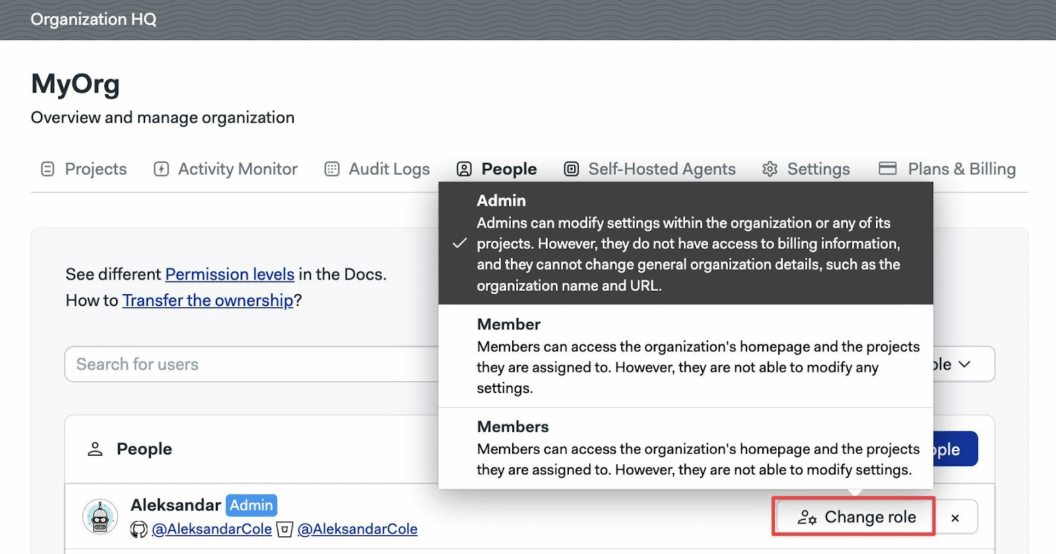
Semaphore ensures security at every step. Keycloak handles authentication, verifying user identities before granting access. RBAC (Role-Based Access Control) enforces fine-grained permissions, ensuring only authorized users can modify configurations or trigger builds.
Wrapping Up
Semaphore is designed to simplify CI/CD without sacrificing power. With automated pipelines, secure access control, and a scalable microservices architecture, it enables developers to ship high-quality software faster.
Now that you have a clearer picture of Semaphore’s inner workings, why not try it out? Whether you’re new to CI/CD or an experienced user, there’s always something to explore. As an open-source project, Semaphore welcomes contributions from the community to continuously improve and enhance its capabilities.
🚀 Ready to get started? Try Semaphore here or contribute to our open-source project and help shape the future of software delivery!
Want to discuss this article? Join our Discord.