At Semaphore, we’ve been rethinking our public API from the ground up.
Over the years, as our platform grew, so did the complexity of our API infrastructure. We tried multiple approaches—some promising, others not so much. The result? A fragmented developer experience that made it harder to integrate, extend, and maintain.
So we decided to change that. This post is about our journey to unify the Semaphore API behind a single, resource-oriented design. To learn more about our journey, listen to our podcast episode or watch the video below! Enjoy!
It’s about making things simpler, more consistent, and easier to use—not just for us, but for every developer who builds on Semaphore.
Where Things Got Messy
Our API has evolved in layers. At one point or another, we were running:
- gRPC APIs that exposed through a reverse proxy, translating HTTP to gRPC.
- Per-service HTTP APIs which were maintained independently.
- A dedicated HTTP server translating requests into internal service calls.
Each method solved problems in its own silo. But together? They made our system hard to reason about and even harder to scale.
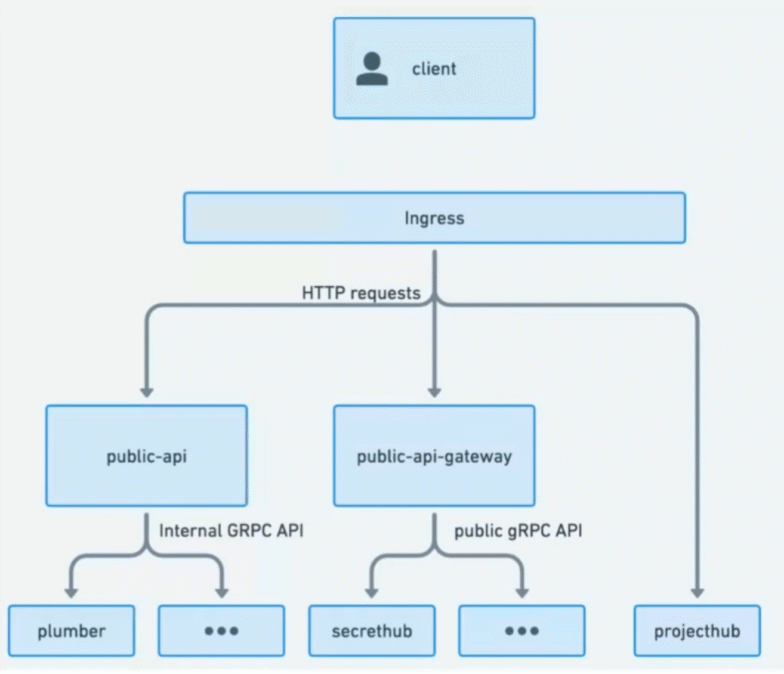
The Turning Point: A Dedicated API Gateway
The most promising approach was the dedicated HTTP gateway: a single service that receives external HTTP requests and translates them into internal gRPC calls.
This gave us several key advantages:
- A single point for applying authentication, validation, and formatting
- One source of truth for the request/response payloads
- Easier maintenance as new features are added
- Consistency in how internal and public APIs communicate
It was such an obvious choice that we leaned in.
Resource-Oriented API Design
To make the API intuitive and extendable, we adopted a resource-oriented design. Inspired by Kubernetes and REST best practices, our resources now follow a consistent structure:
{
"kind": "project",
"metadata": { "id": "proj-123" },
"spec": {
"name": "My App",
"description": "CI/CD pipeline"
}
}kindtells you what type of resource you’re working with.metadataincludes identifiers and timestamps.specholds the actual configuration or desired state.
This pattern makes it easier to reason about objects across the system and gives us room to grow the API without breaking clients.
Richer Representations
Another upgrade we made during design is to include rich object representations of objects instead of their raw IDs.
So, for example, instead of:
"created_by": "user-456"You now get:
"created_by": {
"kind": "user",
"id": "user-456",
"name": "amir"
}This gives consumers more context without extra API calls and sets us up for future extensibility.
Supporting Actions Beyond CRUD
Not all operations fit neatly into create/read/update/delete actions. For example, starting a workflow requires more than just updating a resource.
So we introduced custom methods for resource-specific actions:
POST /projects/{project_id}/workflows/{id}/startThese methods are scoped to the resource, follow predictable naming conventions, and include actionable error messages when things go wrong.
Built with OpenAPI (and Built to Last)
A major part of this overhaul was committing to OpenAPI-first development.
Each endpoint in the API is defined with:
- Typed request and response schemas
- Collocated OpenAPI specs
- Automatic validation and permission checks
- Clear documentation generated from the source
This keeps our docs accurate, reduces drift, and makes the API easier to contribute to and extend.
Inside the Project Structure
Here’s how everything fits together under the one API:
- Handlers: we use one file per endpoint. Each files handles casting, validation, logging, permissions, and forwarding requests.
- Internal clients: we use them as bridges between handlers and gRPC services.
- Formatters: we use them to translate between internal requests and external responses.
We’ve designed things to be modular and clear, so contributors can get up to speed quickly. It’s now easier than ever to add a new endpoint or update an existing one.
Want to Get Involved?
The Semaphore API is open source, and we’d love your feedback.
If you’re a developer who:
- Wants to help improve a real-world API
- Has ideas for how to make things clearer or more consistent
- Likes working with Elixir (or wants to learn!)
Then head over to our GitHub repo, explore the public_api_v2 project, and jump into the issues or discussions.
We’ll also be publishing RFCs for upcoming API design decisions—keep an eye out.
What’s Next
Here’s what’s coming soon:
- Better error handling across all endpoints
- More complete OpenAPI coverage
- Continued unification of all service interactions behind the gateway
- Easier ways to discover and explore available resources
We’re far from done, but we’re on a solid path—and the developer experience is already better than it was just a few months ago.
Final Thoughts
Rebuilding an API isn’t glamorous work. It involves digging into edge cases, rethinking old assumptions, and making a lot of small decisions that add up to a big difference.
But the result? A cleaner, more consistent, and more enjoyable developer experience.
Check out the full talk from Semaphore Summit on YouTube if you want to dive deeper into the architecture and see the code in action.
Thanks for reading—and we hope to see you in the pull requests.
Want to discuss this article? Join our Discord.