What really happens after you push code to your Git repository? Your pipeline kicks off, tests run, and builds are triggered. But, beneath the surface, a complex orchestration engine is making all the right moves.
At Semaphore, that engine is called Plumber.
Plumber is responsible for interpreting pipeline definitions, scheduling jobs, and coordinating execution across distributed agents — all while ensuring reliability and scalability. In this post, I’ll show you:
- How we built it using a finite state machine
- Why we chose Elixir
- How this architecture helps Semaphore scale CI/CD for thousands of developers.
Understanding Semaphore’s Pipeline Model
Semaphore pipelines are made up of blocks and jobs:
- A pipeline defines your CI/CD workflow.
- Blocks group jobs together and define order—sequential or parallel.
- Jobs are execution units that run commands.
- Agents are the machines that actually execute the jobs.

This structure allows teams to model anything from basic test pipelines to complex multi-stage deployments.
From Git Push to Pipeline Execution
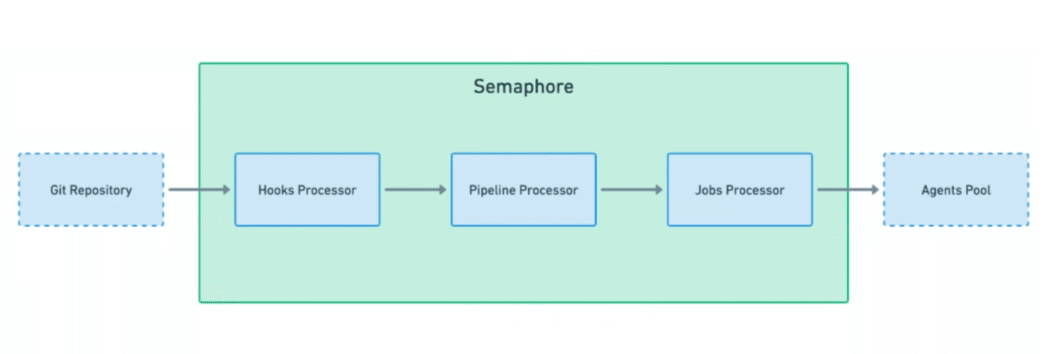
When you push code:
- Your Git provider sends a webhook to Semaphore.
- The Hooks Processor validates and transforms the event.
- The Pipeline Processor—this is where Plumber comes in—fetches the YAML definition and starts orchestration.
- The Job Processor prepares and assigns jobs to available agents.
- Agents execute jobs and report results back to the platform.
Plumber is the service that turns a definition into a real, running pipeline.
Why a State Machine?
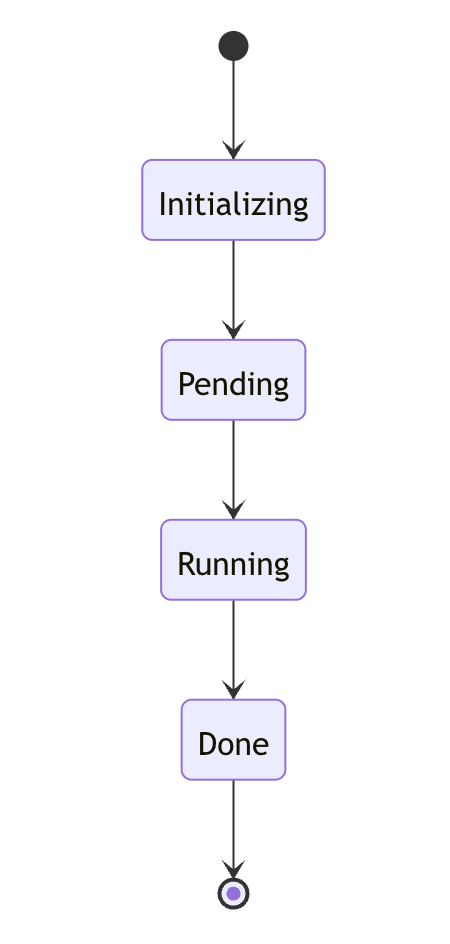
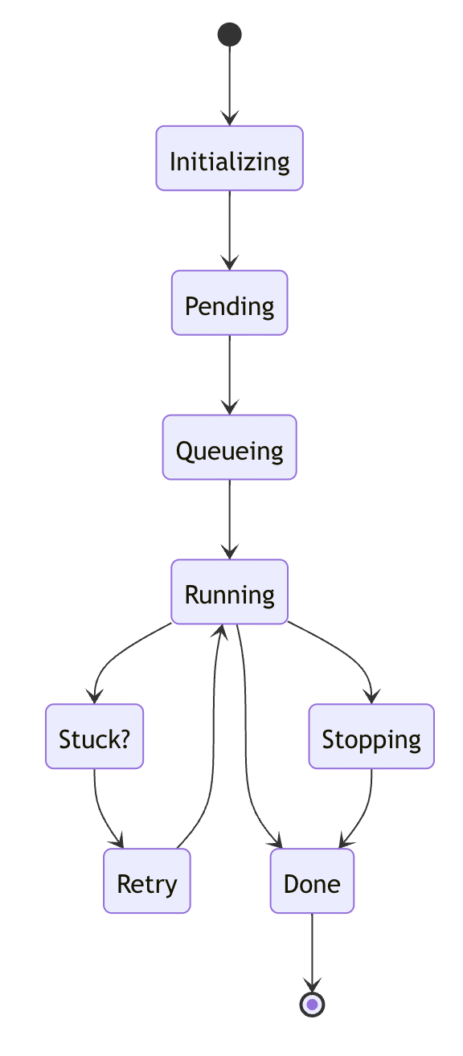
We designed Plumber around a finite state machine (FSM) model. Each pipeline transitions through a known set of states:
- initializing: YAML is parsed and blocks/jobs are created.
- pending: Conditions (like branch filters) are evaluated.
- running: Jobs are executed in the correct order.
- done: The result is finalized and published.
Each state is handled by a dedicated Elixir Looper process that executes state-specific logic. This keeps our system modular, predictable, and easy to maintain.
The Tech Stack
Here’s what powers Plumber:
- Elixir: Built for concurrency, fault tolerance, and lightweight processes.
- PostgreSQL: Provides transactional integrity for all state transitions.
- RabbitMQ: Ensures reliable communication between services.
- Kubernetes: Handles deployment, scaling, and recovery.
This stack lets us scale horizontally, recover from failure, and roll out changes with confidence.
Handling Failures Gracefully
Things can go wrong. A worker might crash mid-job, or an external dependency might fail. To prevent stuck pipelines, we added a stuck state and a recovery loop.
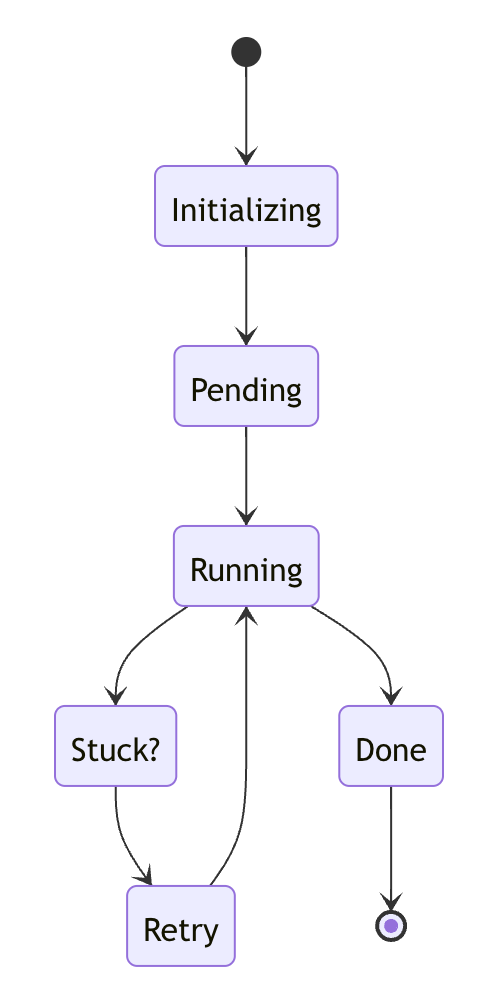
A dedicated recovery worker detects pipelines that have stalled, retries them with exponential backoff, and uses a circuit breaker to stop retrying if the issue persists. This allows the system to self-heal while keeping other pipelines unaffected.
Extending Pipeline Behavior
Thanks to the FSM model, adding new features is straightforward.
Stopping Pipelines Manually
When a user stops a pipeline mid-run, we transition it into a stopping state. All running jobs are halted before the pipeline is done.
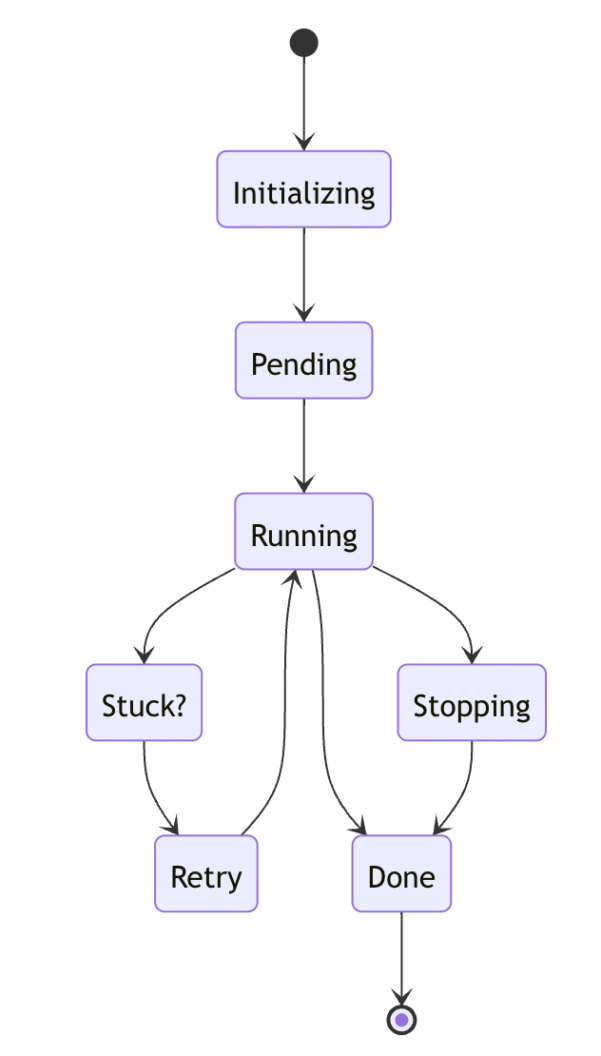
Queuing Pipelines
If multiple commits are pushed to the same branch in a short period, they shouldn’t run in parallel. We added a queuing state so that newer pipelines wait for earlier ones to finish.
Recap: Why It Works
Plumber’s architecture supports the demands of modern CI/CD by focusing on a few key principles:
- Reliability: Supervision trees and Kubernetes health checks keep workers available.
- Scalability: Looper workers scale horizontally across pods.
- Fault Tolerance: Stuck state recovery prevents cascading failures.
- Extensibility: New pipeline logic fits naturally into the state machine.
It’s a system designed to grow with developers’ needs, and it’s been proven in production every day.
Learn More
Semaphore is open source. You can check out the code and dive deeper into how it works:
🔗 Explore it on GitHub
💬 Join our Discord to ask questions (will add link)
📺 Watch related talks on our YouTube channel
Happy building!
Want to discuss this article? Join our Discord.