Testing software in just one environment isn’t enough. Your app may need to work across multiple runtimes, databases, or OS versions. A job matrix automates this by creating parallel jobs for every combination of variables you define.
In Semaphore, job matrices make it easy to expand test coverage, catch regressions early, and keep pipelines clean without writing repetitive job definitions.
To find out more about job matrices, you can listen to the latest Technical Tips podcast episode or watch the video below:
How Job Matrices Work in Semaphore
A job matrix takes variables and their values as input, then generates parallel jobs for all possible combinations. Each variable becomes an environment variable inside the job, so you can reference it directly in your commands.
For example, if you define:
NODE_VERSION = 16, 18, 20DB_BACKEND = mysql, postgres
Semaphore automatically expands this into six parallel jobs (3×2) one for each permutation of the values. This approach eliminates duplication in your pipeline and ensures that every environment you care about is tested consistently.
Creating a Job Matrix in the Workflow Editor
Setting up a job matrix in Semaphore is straightforward:
- Open your workflow editor and create a new block.
- Under Parallel instances, choose Multiple instances based on a matrix.
- Define environment variables and assign multiple values separated by commas.

- Semaphore automatically creates a job for each value. You can reference the variable inside your job commands, just like a regular environment variable.
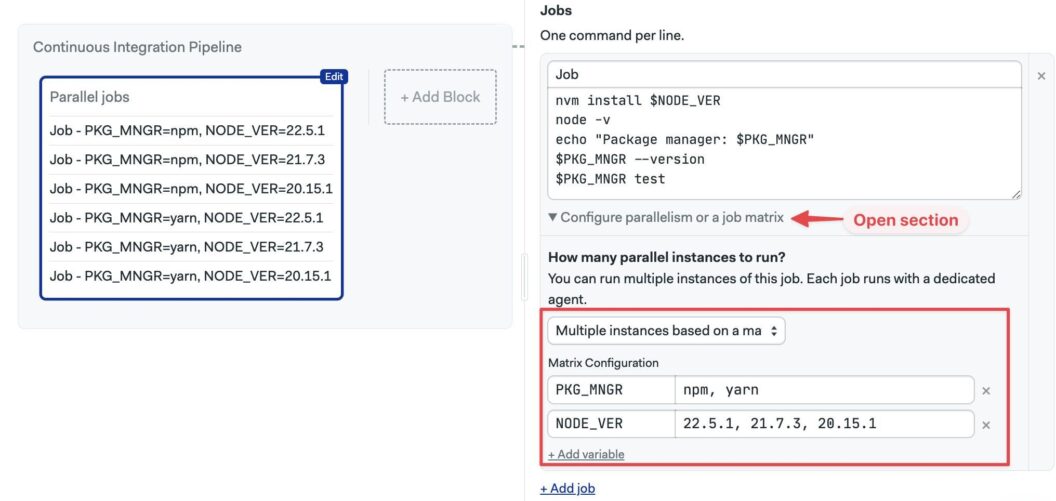
You can define more than one variable. For instance, combining NODE_VERSION with a DB_BACKEND variable (mysql, postgres) generates six jobs; one for each possible combination.
Creating a Job Matrix using YAML
If you prefer configuration as code, you can define a job matrix directly in your .semaphore/semaphore.yml.
Here’s an example:
version: v1.0
name: Continuous Integration Pipeline
agent:
machine:
type: f1-standard-2
os_image: ubuntu2204
blocks:
- name: Job matrix
dependencies: []
task:
jobs:
- name: Job
commands:
- checkout
- sem-version node $NODE_VERSION
- sem-service start $DB_BACKEND
- npm install
- npm test
matrix:
- env_var: DB_BACKEND
values:
- mysql
- postgres
- env_var: NODE_VERSION
values:
- 22.5.1
- 21.7.3
- 20.15.1In this example:
- Semaphore will generate six parallel jobs, one for each Node.js/database combination.
- Each job gets the appropriate
NODE_VERSIONandDB_BACKENDinjected as environment variables. - You can then use these values in your commands as usual.
Try Job Matrices
Job matrices are a powerful way to scale your testing without adding complexity. By defining just a few variables, you can automatically generate parallel jobs that cover multiple runtimes, databases, or environments. This keeps your pipelines clean, your coverage broad, and regressions easier to catch.
If you have any doubts, check the job matrix documentation or contact us on Discord.
Thank you for reading and happy building!
Want to discuss this article? Join our Discord.